本記事はプロモーション(アフィリエイトリンク)を含みます。
FirecrawlをAIエージェントのWeb取得基盤として試すなら、公式ページで最新プランと無料枠を確認できます。
Firecrawl公式サイトを見る「AIエージェントにWebを正確に読ませたい」——そう思ったとき、最初にぶつかる壁がHTMLノイズ問題です。生のHTMLをそのままLLMに渡しても、広告・ナビ・スクリプトの海に埋もれて本文が取り出せません。国内RAGシステムの構築でも同様の課題が報告されており、「AI向けにきれいに整形されたWeb取得」が実務上の急所になっています。
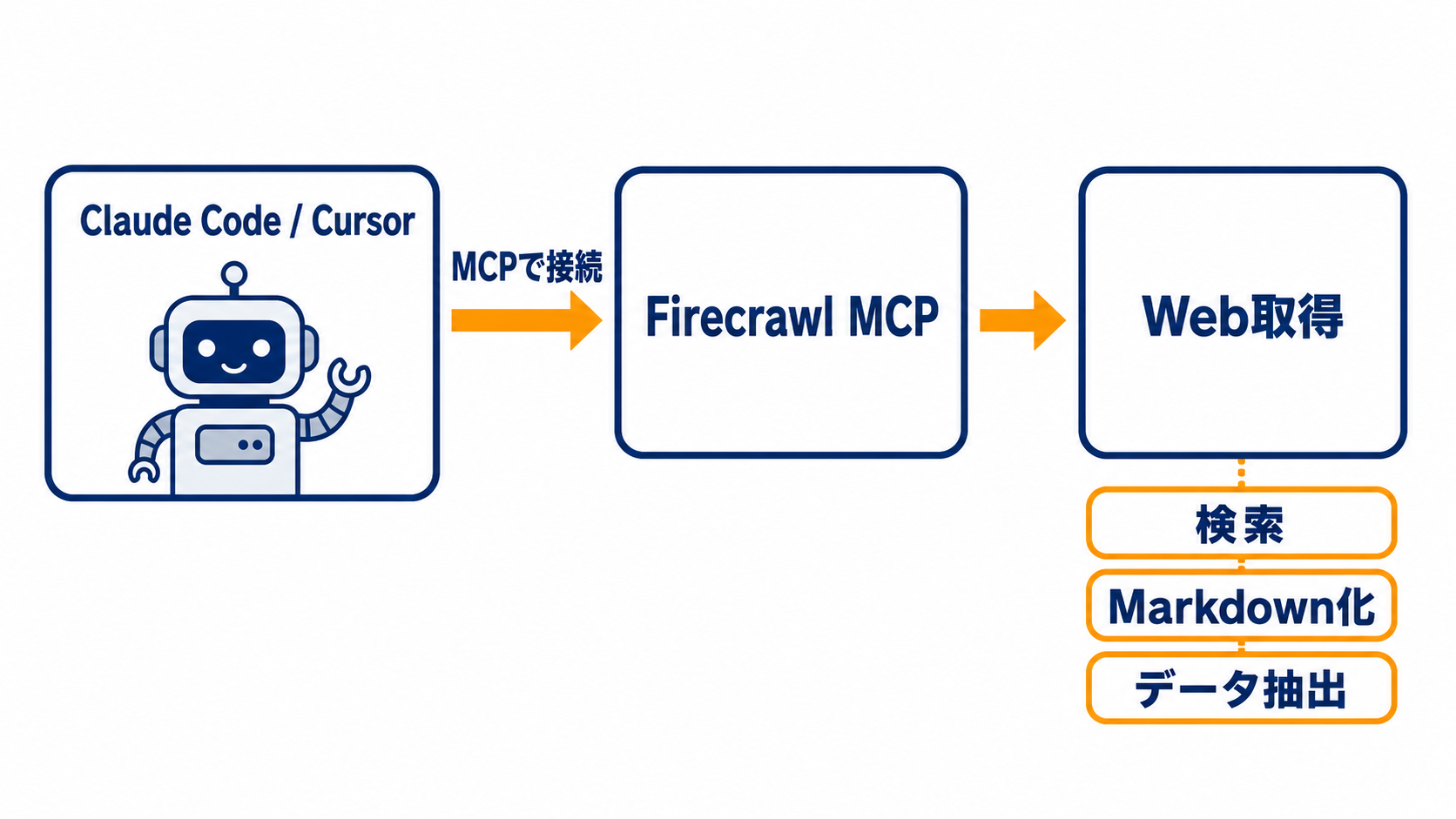
そこで注目されているのが Firecrawl と、その公式 MCPサーバーです。Claude Code・Cursor などのAIエージェント環境からワンコマンドでWebをMarkdown化して返すこの仕組みは、RAGのデータパイプラインや競合監視の自動化に直結します。本記事では2026年時点の公式情報をもとに、設定の流れと実践的な活用例を紹介します。
- Firecrawlが解決するWeb取得の問題と、AIエージェントとの相性
- Firecrawl MCPをClaude Codeに接続するまでの設定の流れ
- RAGデータ収集・競合監視への具体的な活用シナリオ
AIエージェントにWeb取得力を持たせる場合は、MCP対応、API料金、アンチbot対応の違いを比較してください。
Firecrawlとは・なぜAIエージェントに必要か
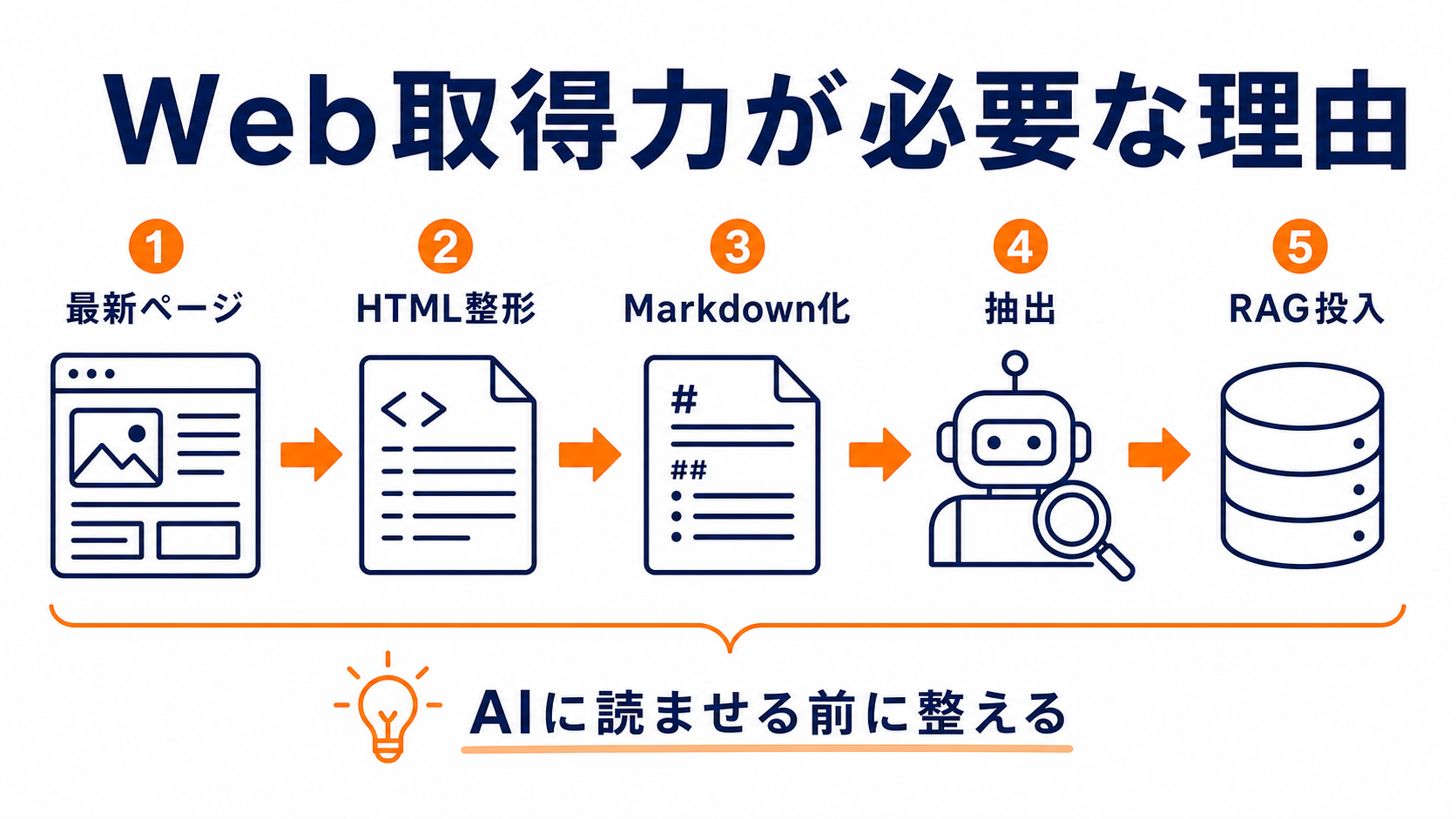
Firecrawlは、WebページをAIが読みやすい形式に変換することに特化したサービスです。公式には scrape・map・search・crawl・extract・batch_scrape など11以上の機能が提供されています。主な機能(一部)は次のとおりです。
- Webスクレイピング(scrape):URLを指定するだけで本文コンテンツを取得
- Markdown化:広告・ナビ・スクリプトを除去し、クリーンなMarkdownに変換
- クロール(crawl):サイト内のリンクを再帰的に辿って大量ページを一括取得
- 構造化抽出(extract):指定したスキーマに従ってデータをJSON形式で抽出
- Web検索(search):キーワードでWebを検索し、結果ページの内容まで取得
- URL探索(map):サイト内に存在するURLを一括で洗い出す
LLMにWebコンテンツを渡す従来手法では、requests+BeautifulSoupで独自パーサーを書くか、Playwright等でレンダリングしてHTMLを渡すかという選択になりがちです。しかしこの方法はJavaScriptレンダリング・ページネーション・Cloudflare対策などで詰まるポイントが多く、保守コストが嵩みます。
- RAGのドキュメント収集で「きれいなMarkdown」を大量に必要とするとき
- 競合他社サイトの価格・機能情報を定期監視したいとき
- JavaScriptで動的に生成されるページのテキストを取得したいとき
- エージェントが自律的にWebを調査するワークフローを構築したいとき
公式のMCPサーバーが提供されていることで、Claude Codeなどのエージェント環境から自然言語で「このURLを取得して」と指示するだけでFirecrawlのAPIを呼び出せるようになります。エージェントがWeb取得のコードを自前で書く必要がなくなり、本来のタスク(分析・生成・判断)に集中できます。
Firecrawl MCPの設定(概要)
ここでは設定の大まかな流れを示します。詳細なコマンドやオプションは常に変更される可能性があるため、公式リポジトリ・ドキュメントで最新情報を確認してください。
Step 1:APIキーの取得
まずFirecrawlの公式サイトからアカウントを作成し、APIキーを発行します。無料プランと有料プランが用意されており、利用可能なクロール数・機能の範囲が異なります。料金の詳細は公式サイトで最新プランを確認してください。
APIキーは環境変数(例:FIRECRAWL_API_KEY)として安全に管理し、コードやgitリポジトリに直接書き込まないようにしましょう。
Step 2:MCPサーバーの設定
Firecrawlは公式のMCPサーバーをnpm経由で提供しています。Claude Codeでは .mcp.json(またはグローバルMCP設定ファイル)にサーバー定義を追記することで接続できます。設定の骨格は以下のようなイメージです(実際のキー名・バージョン等は公式ドキュメントを参照)。
{
"mcpServers": {
"firecrawl": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "YOUR-API-KEY"
}
}
}
}MCPサーバーのパッケージ名・引数・環境変数名は2026年以降も更新される可能性があります。実際の設定は Firecrawl公式ドキュメントのMCPセクションで確認してください。
Step 3:Claude Codeから呼び出す
設定完了後、Claude Codeのチャット欄で自然言語ベースの指示を出すだけでFirecrawlが動作します。
- 「https://example.com のコンテンツをMarkdownで取得して」
- 「このサイトのトップ10ページをクロールして構造化データとして抽出して」
- 「競合サイトの料金ページから価格テーブルをJSONで出して」
エージェントがFirecrawlのAPIを自律的に呼び出し、整形済みの結果を返してくれます。Cursorなど他のMCP対応エディタでも同様の接続が可能です。
活用例:RAGデータ収集と競合監視
活用例①:RAGのデータパイプライン自動化
RAGシステムでは、検索対象となるドキュメントの品質がそのまま回答精度に直結します。Webを情報源にする場合、Firecrawlを使うと次のフローが実現できます。
- AIエージェントが対象URLリストをFirecrawl MCPに渡す
- FirecrawlがMarkdown変換・クリーニングを行って返す
- エージェントがそのままベクターDBに格納する
従来は「スクレイピング→パース→クリーニング」を自前で組む必要がありましたが、Firecrawlがこのパイプラインの前段をまるごと担ってくれます。Dify等のノーコードRAG基盤(Dify×さくら構成についてはこちらの記事で解説しています)と組み合わせると、コーディングなしでWebを知識源にしたチャットボットが構築できます。
活用例②:競合サイトの定期監視
SaaSやECでよくある「競合の料金改定・機能追加をいち早く知りたい」というニーズにもFirecrawlは有効です。
- 競合の料金ページ・リリースノートURLをリストアップ
- Claude Codeのエージェントが定期的にFirecrawlで取得
- 前回取得との差分をLLMが分析し、変更点をSlackやメールに通知
JavaScriptで動的生成されるSPAページも、FirecrawlがヘッドレスブラウザでレンダリングしてからMarkdown化するため、従来のHTTPクライアントでは取得できなかったコンテンツにも対応できます(対応可否は公式ドキュメントで確認を)。
よくある質問
Q. Firecrawlは無料で使えますか?
A. 2026年時点で無料プランが提供されていますが、月あたりのクロール数や取得ページ数に制限があります。本番運用や大量取得を想定する場合は有料プランが必要になることが多いです。最新の料金・制限は公式サイトで確認してください。
Q. Claude Code以外のエージェント環境でも使えますか?
A. はい。FirecrawlはModel Context Protocol(MCP)の仕様に準拠した公式サーバーを提供しているため、MCP対応のクライアント(CursorやClineなど)であればほぼ同様の手順で接続できます。詳細は各ツールのMCP設定ドキュメントを参照してください。
Q. JavaScriptで生成されるページ(SPA)は取得できますか?
A. Firecrawlはヘッドレスブラウザを使ったレンダリングに対応しており、SPAやクライアントサイドレンダリングのページも取得できるとされています。ただし対象サイトの構造・アンチスクレイピング対策によっては取得できない場合もあるため、事前の動作確認を推奨します。
Q. スクレイピングの利用規約上の問題はありますか?
A. Webスクレイピングは対象サイトの利用規約(ToS)で禁止されているケースがあります。Firecrawlを使う際も、robots.txtの遵守や対象サイトのToSの確認は利用者側の責任です。また取得したデータの二次利用・商用利用については著作権も考慮してください。
まとめ
Firecrawl MCPは、AIエージェントが「Webをそのまま読む」という課題をエレガントに解決するツールです。
- FirecrawlはWebページをAI向けにスクレイピング・Markdown化・構造化抽出するサービス
- 公式MCPサーバーをClaude Codeに接続することで、エージェントが自律的にWebを取得できる
- APIキー取得 → MCP設定 → Claude Codeから自然言語で呼び出す、の3ステップで導入可能
- RAGのデータ収集・競合監視など、実務のWeb取得タスクを大幅に省力化できる
- 料金・最新仕様は公式サイトで必ず確認すること
AIエージェントに「Web取得力」を与えることで、単発の質問応答を超えた自律的な情報収集・分析ワークフローが現実になります。まずはAPIキーを取得して、Claude Codeとの接続を試してみてください。
RAG・競合調査・自動収集の実装前に、FirecrawlのAPI仕様と料金を確認しておきましょう。
Firecrawlを確認する