RunPodは「GPUを買わずに必要な時だけ借りる」クラウドGPUサービスです。OSSのLLM実行・画像生成・音声STT/TTS・Difyのバックエンドなど、個人開発者がAIエージェントを動かす用途にフィットします。料金は時間課金の従量制で変動するため、最新の単価は必ず公式サイトで確認してください。

RunPodとは・何に使う
RunPodは、GPUを時間単位で借りられるクラウドGPUサービスです。AWSやGCPのような大手クラウドと異なり、GPU利用に特化した設計になっており、個人開発者や研究者が気軽に使いやすい料金設定と UI を持っています。
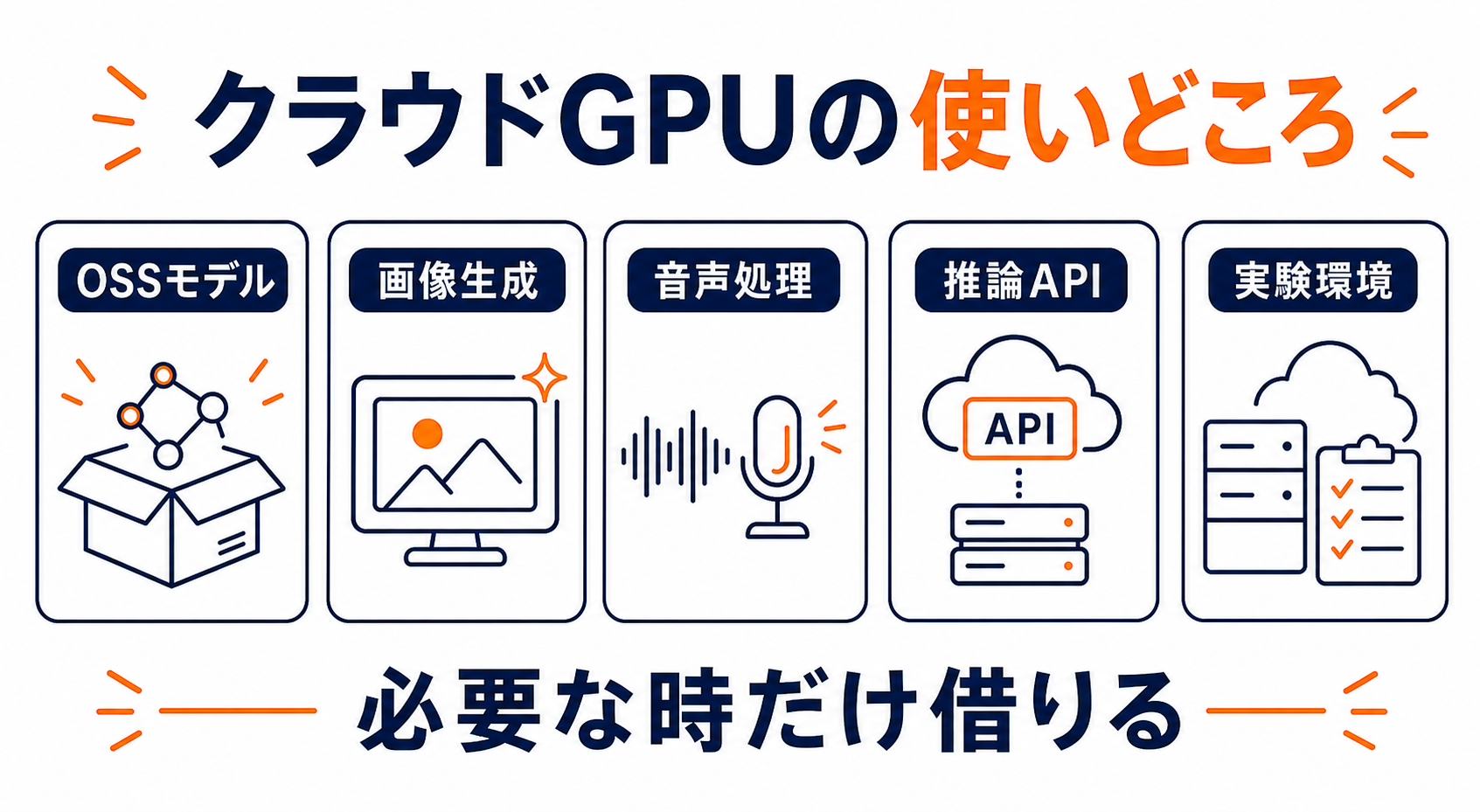
主な利用シーンは次の通りです。
- OSS LLMの実行:LlamaやMistralなどのオープンウェイトモデルをvLLMやOllamaで動かす
- 画像生成:Stable DiffusionやFLUX系モデルをAPIとして立ち上げる
- 音声処理(STT/TTS):WhisperやCoqui TTSなど音声AIモデルの推論
- AIエージェントのバックエンド:DifyやLangChainで組んだパイプラインのLLM推論部分をRunPodに委譲
「APIだと月額コストが怖い」「自前モデルを動かしたい」「GPUを買う前に試したい」という個人開発者・エンジニア。ゼロからGPUサーバを構築するより圧倒的に早く始められます。
RunPodの提供形態は2026年時点でPods(単一GPUインスタンス)・Serverless(オートスケール)・Instant Clusters(マルチノード)・Bare Metal(専有物理GPU)の4種類があります。中心となるのはPodsとServerlessで、ほかにInstant Clusters・Bare Metalもあります。Serverlessはリクエストベースで課金され、コールドスタートを許容できる用途向け。Podsは常時起動型で、レイテンシが重要な用途や開発・デバッグに向いています。
料金の考え方(従量課金)
RunPodの料金は時間課金の従量制です。GPUの種類(VRAM容量・世代)によって単価が変わり、需給によっても変動します。そのため本記事では具体的な金額を断定しません。
GPUの空き状況や市場需要によってスポット価格は常に変動します。また料金体系そのものが改定されることもあります。必ずRunPod公式サイトで最新の価格を確認してください。
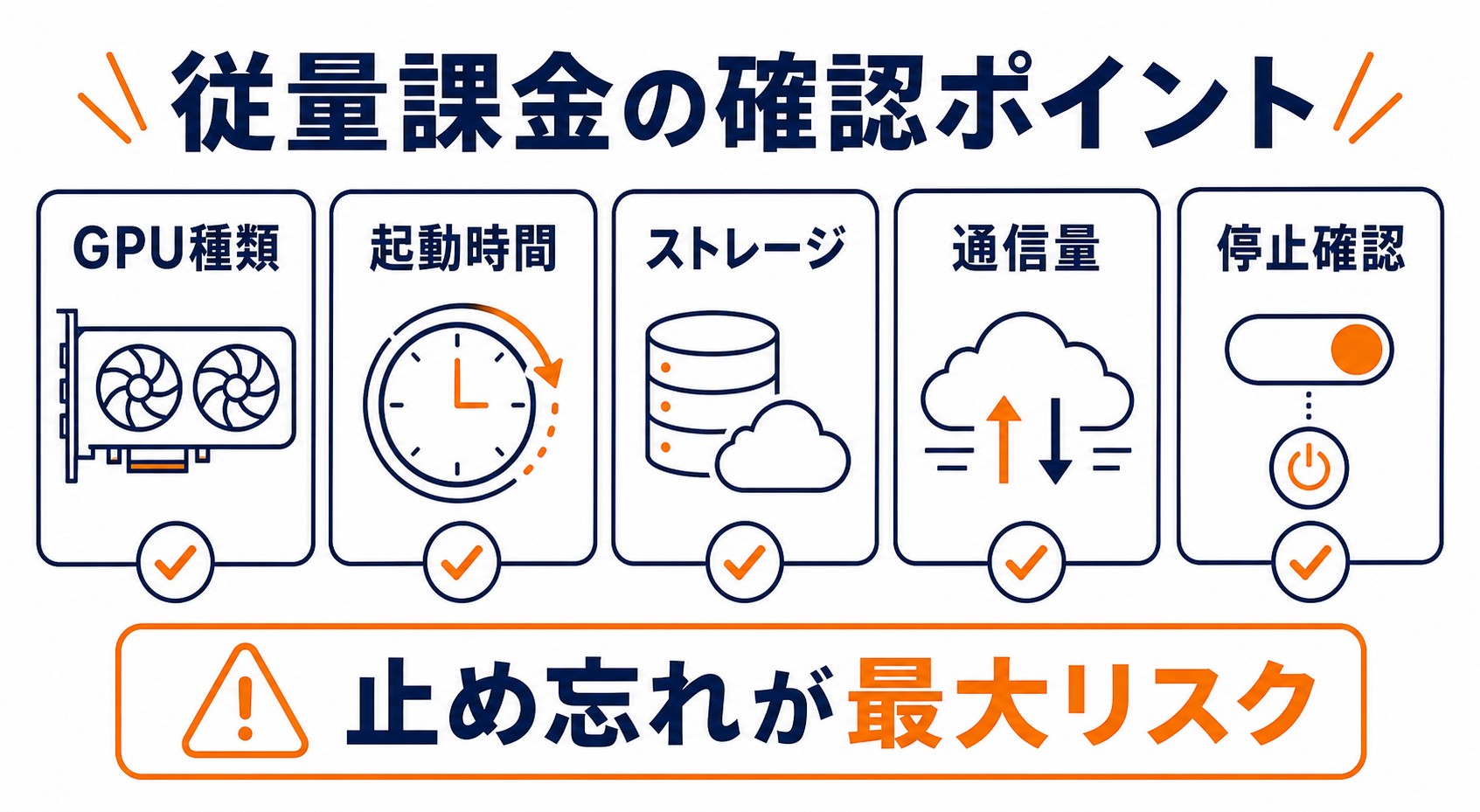
料金を考える上での基本的な考え方を整理すると:
- GPU種別で価格帯が変わる:エントリー向けのGPUは低単価、高VRAM・最新世代のGPUは高単価
- Spot(スポット)とOn-Demand(オンデマンド)がある:スポットは安いが強制終了リスクあり。開発・実験はスポット、本番はオンデマンドが基本方針
- ストレージ料金も別途かかる:Podのボリュームサイズに応じた保存料金が発生
- Serverlessは実行時間ベース:常時起動コストが不要なためバースト用途でコスト効率が良い
個人開発者が最初に試す場合、少額のクレジットで短時間のテストを繰り返すのが失敗しにくいアプローチです。
始め方(概要)
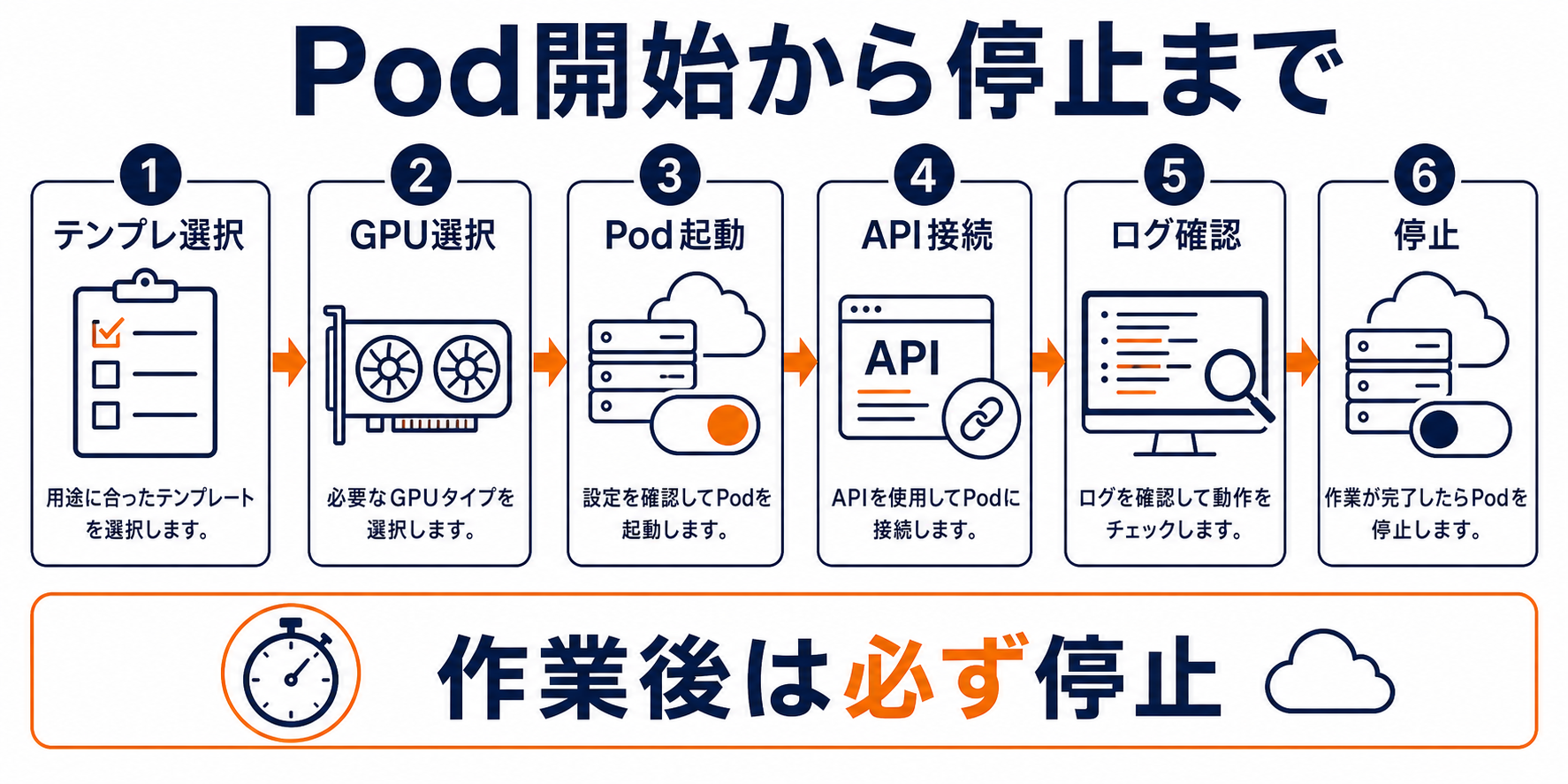
RunPodのアカウント開設から最初のGPU起動まで、大まかな流れは以下の通りです。細かいUIは変更されることがあるため、詳細は公式ドキュメントを参照してください。
- アカウント作成:runpod.ioでメール登録
- クレジットのチャージ:クレジットカード等で残高を追加(プリペイド式)
- Podの選択・起動:GPU種別・テンプレート(DockerイメージやRunPodプリセット)を選んで起動
- 接続:JupyterLab・SSH・HTTP APIエンドポイントでアクセス
- 作業後は必ず停止・削除:起動したままにすると課金が続くため、不要なPodは削除する
RunPodにはvLLM・Stable Diffusion・Whisperなど人気ツールのテンプレートが用意されています。一から環境構築しなくても数分でモデルを動かせるのが利点です。
AIエージェント / OSSモデルでの活用
RunPodは特に、AIエージェントのLLM推論バックエンドとしての利用が広がっています。
DifyのカスタムLLMバックエンドとして使う
DifyはOpenAI互換のAPIエンドポイントを設定できます。RunPodでvLLMを起動し、そのエンドポイントをDifyに登録すれば、OSSモデルをDifyのワークフローで利用できます。国内VPSにDifyを自前ホストしている場合、RunPodのGPUをAPIバックエンドとして組み合わせる構成が有効です。
→ Difyの自前ホストについてはDifyを国内VPSに自前ホストする方法も参照してください。
OSSモデルの推論APIとして使う
vLLM・Ollamaをテンプレートから起動し、OpenAI互換の推論エンドポイントとして利用できます。LangChain・LlamaIndex・その他エージェントフレームワークから簡単に接続できます。
音声STT/TTSの処理に使う
WhisperやCoqui TTSなど音声モデルはGPUがあると処理速度が大幅に上がります。RunPodで必要な時だけGPUを起動し、音声処理をバッチ実行する使い方はコスト効率が良いです。
RunPodのサーバーは海外拠点が多いです。レイテンシが重要なリアルタイム用途では注意が必要です。また単一Podは可用性保証がないため、本番ユーザー向けサービスには冗長構成の検討が必要です。
よくある質問
Q. RunPodは日本語で使えますか?
UIは英語ですが、操作自体は難しくありません。ドキュメントも英語が中心ですが、コミュニティやブログの日本語解説も増えています。最新情報は公式ドキュメント(英語)が一次情報です。
Q. 支払いはどのように行いますか?
クレジットカードで残高をチャージするプリペイド方式が基本です。使った分だけ残高が減ります。詳細な支払い方法はRunPod公式サイトで確認してください。
Q. 無料で試せますか?
無料クレジットの提供状況は時期によって変わります。現在の無料枠・トライアルの有無は公式サイトのサインアップページをご確認ください。少額のチャージから始めて試す方法が現実的です。
Q. Podを止め忘れると料金はどうなりますか?
起動中のPodは時間課金が続きます。残高が約10分相当まで減ると自動的に停止され(0 GPUの状態で再起動するためデータの取り出しは可能です)、想定外の課金を防げます。ただし残高が完全に枯渇するとPodと関連ストレージが削除され、復旧できない場合があります(RunPodはバックアップを保持しません)。データ消失を防ぐため、auto-pay(自動チャージ)の設定と外部へのバックアップ、そして作業後は必ずPodを停止・削除する習慣を強く推奨します。
まとめ
- RunPodはGPUを時間課金で借りられるクラウドサービス。個人でも気軽に使える
- OSS LLM・画像生成・音声AI・Difyバックエンドなど、AIエージェント開発に幅広く活用できる
- 料金は従量制で変動するため、具体的な単価は必ず公式サイトで確認
- Spot vs On-Demand・Serverless vs Pods を用途に合わせて使い分けるのがコツ
- Podの停止・削除を忘れないことが最大のコスト管理術